The Economist opublikował niedawno daily chart, którego tytuł w kontekście panujących nastrojów społecznych brzmi jak prowokacja: Why Europe needs more migrants. Każdy kto zna “Ekonomistę” wie jednak, że to pismo reprezentujące trzeźwy, ekonomiczny racjonalizm w opozycji do wszelkich ideologicznych idiosynkrazji, więc jeśli prowokuje, to przede wszystkim do myślenia.
Choć o sytuacji demograficznej już pisaliśmy, i to dosyć obszernie, na moment wracam więc do tego tematu. Trudno oprzeć się bowiem wrażeniu, że ktokolwiek się nim zajmuje w debacie publicznej – od rządzących po Make Life Harder – myślenie to jest obciążone: (a) fiksacją na dzietności, (b) marginalizacją ekonomicznej roli imigracji. Zrekapituluję krótko te dwa błędne mniemania.
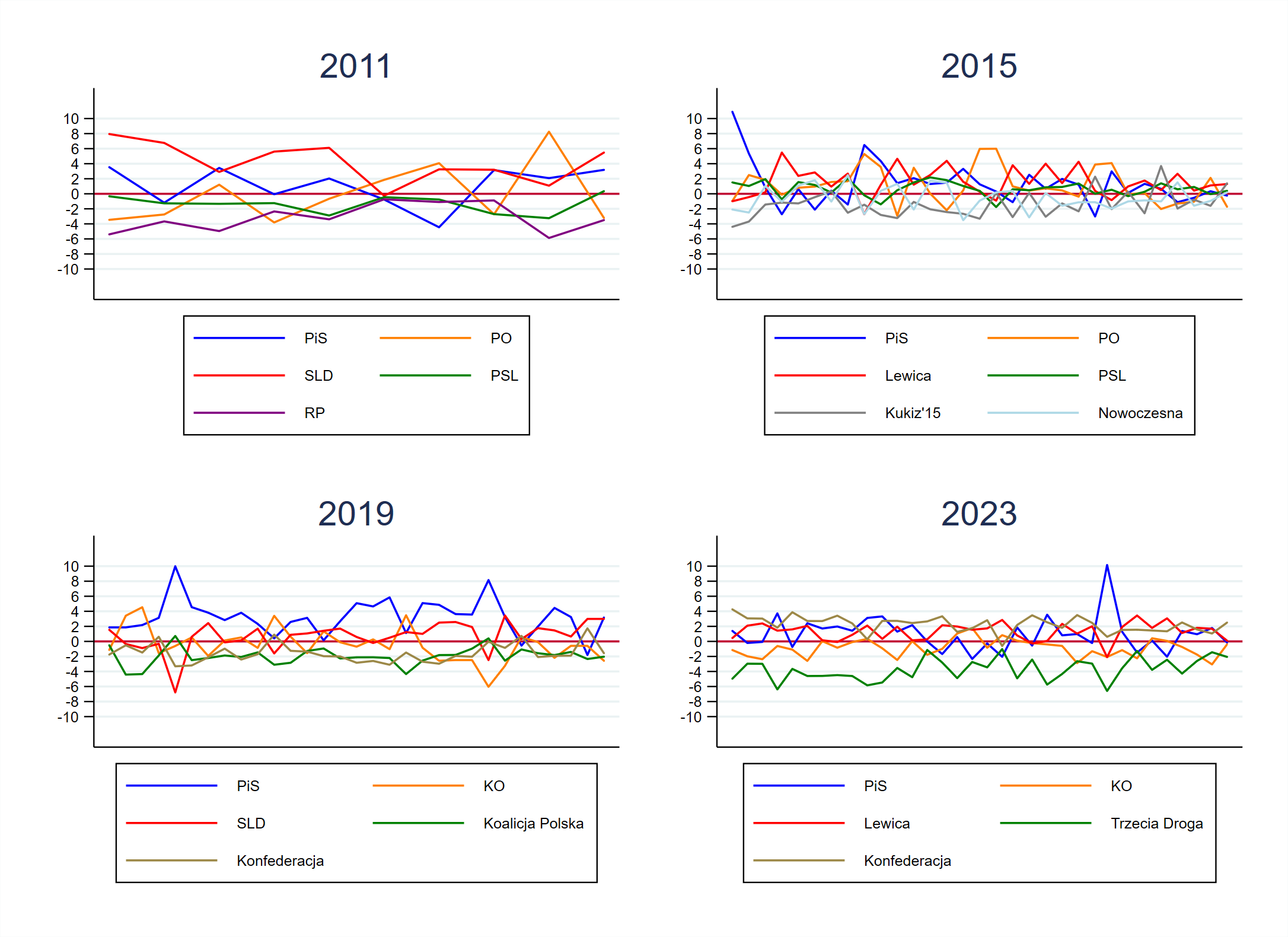
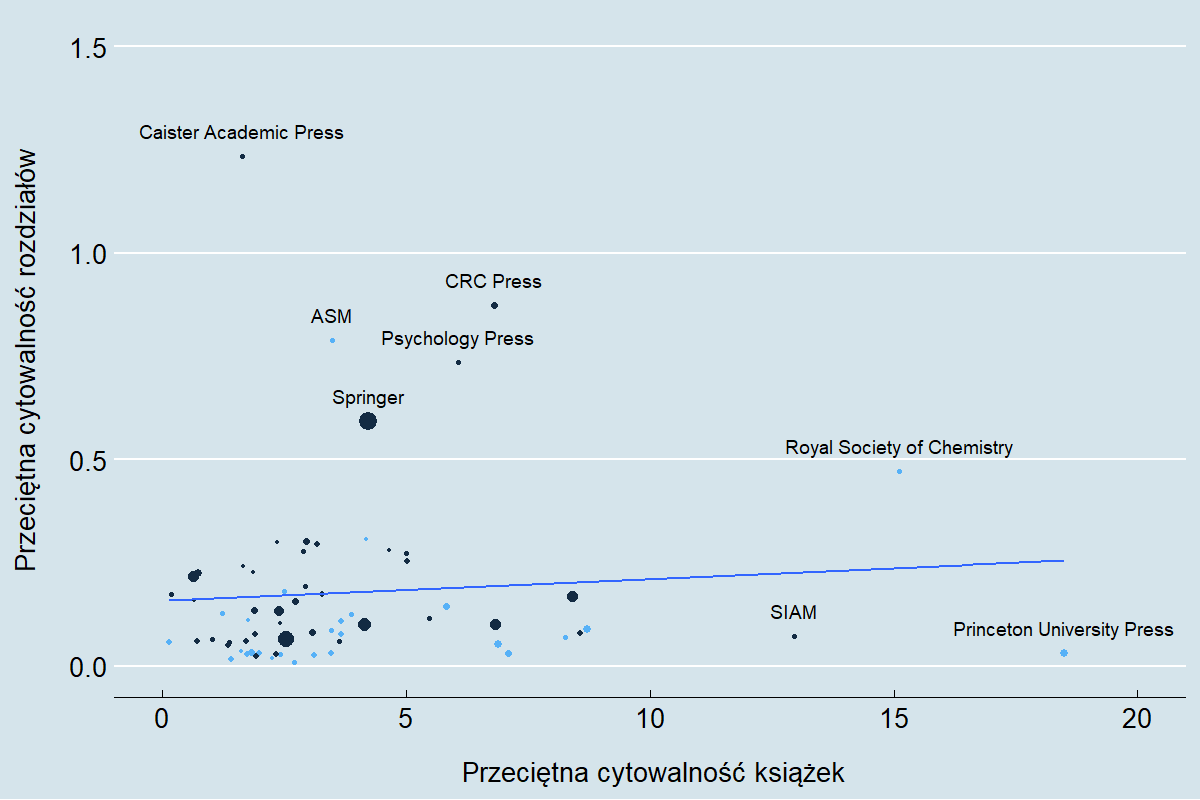
“Mit dzietności” zakłada, że (1) wyższa dzietność może samodzielnie rozwiązać problemy demograficzne współczesnej Polski, a także, że (2) zapewnienie zastępowalności pokoleniowej jest dziś w Polsce realne. Aby najprościej wyjaśnić na czym polega mylność tych przekonań zacznijmy od możliwie najprostszej ilustracji – sztafety pokoleń. Na wykresie poniżej przedstawione zostały liczebności 10-letnich kohort wiekowych współczesnych Polek (dane GUS z VI 2017). Ograniczymy się do kobiet, ponieważ to właśnie ich bezpośrednio dotyczą statystyki dzietności. Przeciętny wiek urodzenia dziecka to obecnie 29 lat. Przyjmując kilka interpretacyjnych uproszczeń możemy więc spojrzeć na te kohorty jako na sekwencję grup matek i córek oddzielonych od siebie interwałem 30 lat. Takiej interpretacji można postawić szereg słusznych zastrzeżeń1, ale mimo wszystko będzie to wystarczające przybliżenie realnych prawidłowości.
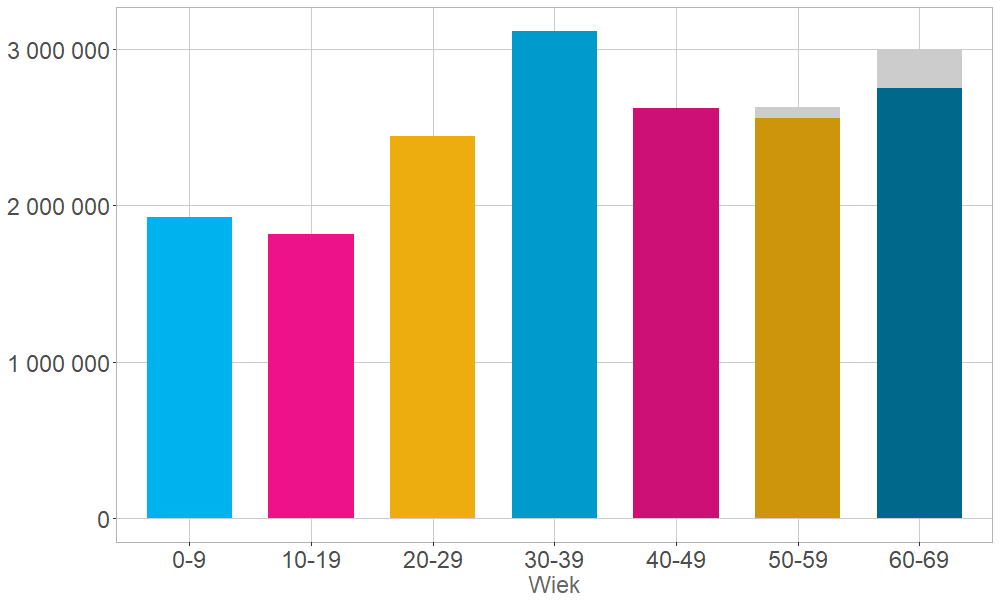
Wielkość kohort demograficznych w populacji współczesnych Polek (stan na 30 VI 2017 wg GUS)
Do oznaczenia na wykresie poszczególnych “sztafet pokoleniowych” użyłem osobnych palet kolorystycznych. Kobiety w wieku 60-69 lat to “kohorta matek” dla kobiet w wieku 30-39 lat, te z kolei to “statystyczne matki” dziewczynek w wieku 0-9 lat. Analogiczną relację możemy zdefiniować dla dzisiejszych pięćdziesięcio- i dwudziestolatek, a także dla czterdziesto- i nastolatek.
Co widzimy na wykresie? Jeśli porównamy kohortę 60-69 z ich “córkami”, to widać, że kobiety urodzone tuż po II wojnie światowej wydały na świat przeciętnie więcej niż jedną córkę. Nie zmienia tego nawet wzięcie pod uwagę rosnącej śmiertelności kobiet po 50-tce – owe “ubytki” skompensowane są szarą “czapką” na dwóch ostatnich słupkach (śmiertelność młodszych kobiet jest niska, została więc pominięta). Dla kolejnych grup wiekowych ta tendencja wyraźnie się zmienia. Córki kobiet w wieku 50-59 lat, czyli dzisiejsze 20-latki, są mniej liczne niż ich matki. Dramatyczny spadek zaczyna się jednak dopiero w kolejnych grupach. Sukcesję ponad 3 milionom dzisiejszych 30-latek zapewnia zaledwie 2 miliony dziewczynek poniżej 10 roku życia.
Co z tego wynika? Po pierwsze trzeba rozumieć, że żaden ze słupków nie powiększy się już samym ruchem naturalnym. Dzisiejsza kohorta nastolatek nie zrobi się większa niż 2 miliony. Niezależnie więc od wskaźnika liczby urodzeń, nie zwiększy się liczba przyszłych matek. Nawet gdyby trend niskiej dzietności został kompletnie zatrzymany, nie ma powrotu do liczebności Polek z wyżu lat 1980-ych.
Ale czy ten trend można zatrzymać? Współczynnik dzietności (przeciętna liczba dzieci przypadających na kobietę w wieku rozrodczym) wynosi w Polsce niewiele ponad 1,3 (czyli statystycznie każda matka ma ok. 2/3 córki). To bardzo mało, ale w Europie jedynie dwa kraje balansują na poziomie odtwarzalności pokoleń, czyli mają ten współczynnik na poziomie około 2, są to Francja i Irlandia. Przypomnijmy jednak – jest to poziom odtwarzalności, a nie przyrostu, więc dylemat dotyczy samego utrzymania liczebności tych najmniej licznych kohort (sic!). Co więcej, takiej energii w płodzeniu dzieci nie obserwujemy nigdzie na wschód od Renu, a my wypadamy pod tym względem blado nawet na tle samych sąsiadów (zob. interaktywny wykres na Google).
Aby osiągnąć przeciętną dzietność na poziomie 2 – której Polska w ogóle nie notowała od 1991 roku – kobiety musiałyby rodzić w wyraźnie młodszym wieku i w związku z tym masowo rezygnować z innych życiowych planów. Nie chodzi nawet o realizację marzeń o karierze na szczytach władzy i bogactwa, czy o podróży dookoła świata, ale o rzeczy znacznie bardziej rudymentarne, takie jak studia. Przypomnijmy, że współczynnik skolaryzacji brutto na poziomie szkolnictwa wyższego wynosił na początku lat 1990-ych niewiele ponad 10%, ale w 2010 roku przekroczył 50%. Już sama masowość studiów wyższych przesuwa większość decyzji prokreacyjnych na okres po 25. roku życia. Do pewnych rzeczy po prostu nie ma powrotu, chyba, że w scenariuszu Handmaid’s Tale.
Warto także pamiętać, że programy child benefit, analogiczne do 500+, posiada większość państw europejskich, więc ze względu na konwergencję tak instytucji, jak stylów życia względnie bezpieczne wydaje się założenie, że dzietność w Polsce może w nadchodzących latach wzrosnąć, ale co najwyżej do poziomu 1,5-2,0. W najbardziej optymistycznym z tych scenariuszy (i biorąc na razie w nawias migracje) za 40 lat wykres “sztafety matek i córek” wyglądałby mniej więcej tak jak na wykresie poniżej2. Czarne obrysy oddają wielkość kohort z pierwszego wykresu, czyli tych dzisiejszych. Globalnie oznacza to spadek populacji o około 28% (przypomnijmy – to wersja optymistyczna!). Ale – i to jest szczególnie uderzające – w wersji „pesymistycznej” (czyli przy współczynniku dzietności na obecnym poziomie 1,3), sprawa przedstawia się w zasadzie niewiele gorzej – spadek wyniesie 33%. Jak widać optymizm i pesymizm w sprawie dzietności niewiele się różnią – konik i tak już uciekł. Wyższy współczynnik urodzeń w ogólnym rozrachunku może nieco poprawić sytuację demograficzną, ale fiksowanie się na dzietności jako rozwiązaniu problemu starzenia się społeczeństwa jest nieracjonalne.
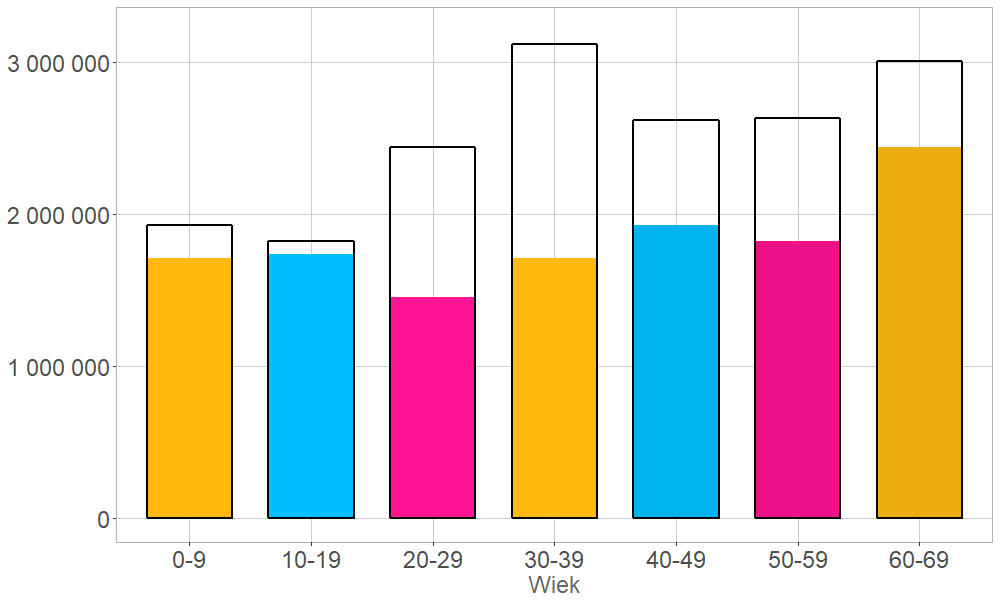
“Sztafeta demograficzna” z poprzedniego wykresu za 40 lat przy założeniu o rosnącej dzietności.
Przejdźmy zatem do kwestii imigracji. W dobie kryzysu migracyjnego jest to sprawa drażliwa, ponieważ została spleciona z gorącymi wątkami politycznymi, w tym z lękami o bezpieczeństwo i tożsamość. Jednak niezależnie od towarzyszących jej emocji warto patrzeć na nią trzeźwo – system emerytalny potrzebuje czynnych zawodowo, a rozwijająca się gospodarka – rąk do pracy. Jest jasne, że firmy będą poszukiwały pracowników nawet jeśli rodzima podaż się wyczerpie. Presja popytu na pracownika odczuwana jest na razie głównie w postaci rekordowo niskiego poziomu bezrobocia, ale gospodarka już od dawna “zasysa” też pracowników z zagranicy.
Kwestię emigracji i imigracji zarobkowej, jak wszystkie inne zjawiska ekonomiczne, wypada rozpatrywać w kategoriach podaży i popytu. Patrząc na dane GUS dotyczące ruchów ludnościowych do i z Polski widzimy, że wciąż więcej osób wyjeżdża, niż przyjeżdża. Poniższy wykres pokazuje migracje na stałe, czyli (wg GUS) na co najmniej 12 miesięcy. Czarna ramka pokazuje ubytki ludnościowe, zaś czerwone wypełnienie – stopień ich bieżącego uzupełniania przez przybyszy z zagranicy. Są to jedynie przybliżenia i nie uwzględniają wszystkich rodzajów przepływów ludnościowych (o tym za chwilę), jednak ta wystandaryzowana miara daje pewne pojęcie o atrakcyjności migracyjnej naszego kraju. W ostatnich latach wciąż więcej ludzi długotrwale opuszczało Polskę, niż do niej na stałe przybywało, choć widać jednocześnie trend zmniejszania się tej różnicy. W odróżnieniu od kwestii przyrostu naturalnego, tu państwo ma realny i dużo bardziej znaczący wpływ na konsekwencje demograficzne – oznacza to, że w odróżnieniu od wykresu ilustrującego odtwarzalność pokoleniową, tu dużo trudniej przewidzieć dalszy trend bez wiedzy o konkretnych decyzjach politycznych. Jednak ze względu na wspomniane kwestie popytowo-podażowe, instytucjonalny wpływ na bilans migracyjny również nie jest nieograniczony.
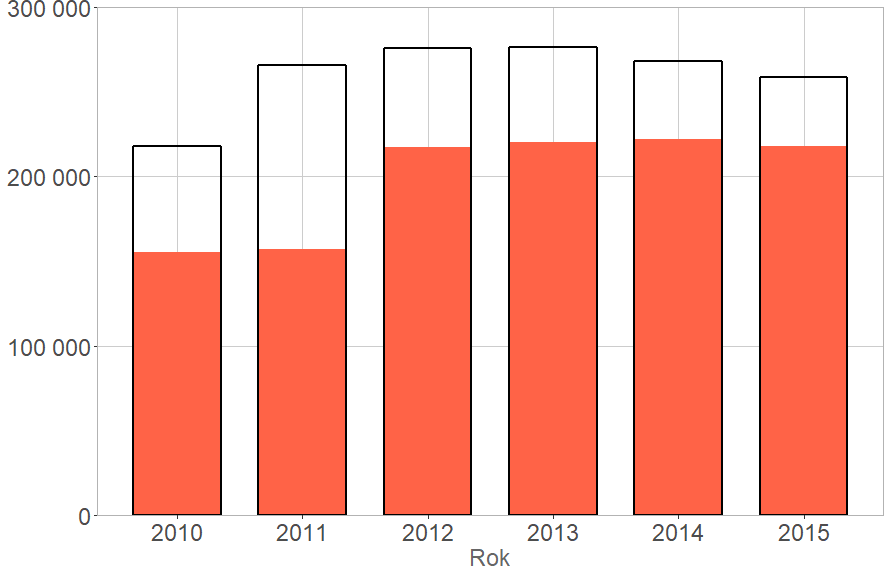
Stosunek emigracji (czarna ramka) do imigracji (czerwone wypełnienie), dane GUS.
Tu dochodzimy do mitu nr 2. Jest nim przekonanie, że polityka imigracyjna może sprowadzać się do zamknięcia drzwi na osoby spoza Unii Europejskiej (czy szerzej rozumianego Zachodu). Jest tak, ponieważ Polska wraz z Chorwacją, Rumunią i Bułgarią zamyka stawkę, jeśli idzie o poziom życia szeroko rozumianego Zachodu. Sami imigranci również dokonują wyborów, więc obie strony potrafią być swoiście „wybredne”. Jedynie kraje najbardziej zamożne, takie jak Wielka Brytania, USA czy Niemcy mogą regulować napływ imigrantów jedynie przez selekcję negatywną.
Jedna z lansowanych obecnie koncepcji zakłada, że imigrację można skutecznie zastąpić reemigracją i repatriacją, a liczba emigrantów z Polski i osób polskiego pochodzenia jest do tego wystarczająca. Jednak największe zagraniczne społeczności polskie są na Zachodzie (dwa największe ośrodki to USA i Niemcy), więc jest to równoznaczne z oczekiwaniem porzucenia przez ludzi lepiej płatnej pracy i lepszych perspektyw życiowych, jakie oferują im te kraje. Na wschód od Polski największym ośrodkiem jest natomiast Białoruś, ale zamieszkuje tam ok. 300 tys. osób deklarujących polskie pochodzenie, więc nawet przyciągnięcie całej mniejszości polskiej z terenu byłego ZSRR – biorąc w nawias realne możliwości i koszty – miałaby marginalne skutki ekonomiczne (dodajmy, że w okresie 1997-2016 Polska wydała 5908 formalnych wiz repatriacyjnych). Być może niektórzy dopatrują się także szansy w negatywnym rezultacie negocjacji dotyczących Brexitu. Zostawmy jednak różnego rodzaju złudzenia i przyjrzyjmy się faktom.
Realnie rzecz biorąc, doraźne rozwiązanie braku dodatkowych rąk do pracy trafiło się Polsce wyjątkowym zbiegiem okoliczności. To czego nie widzimy na powyższym wykresie to liczna rzesza pracowników przyjeżdżających na krótki okres. Liczbę formalnie wydanych nowych zezwoleń na pracę ilustruje kolejny wykres (poniżej), a trzeba mieć na względzie, że jest ona dużo niższa niż realna liczba pracujących w Polsce Ukraińców3. Począwszy przynajmniej od 2014 roku napływ siły roboczej do Polski jest zatem realnie większy niż odpływ, ponieważ podaż pracy skutecznie „suplementowana” jest masowymi przyjazdami krótkookresowymi z Ukrainy (ponad 80%). Warto w tym kontekście postawić pytanie: kto zastąpiłby tych pracowników, gdyby na Ukrainie panował pokój i kwitła gospodarka?
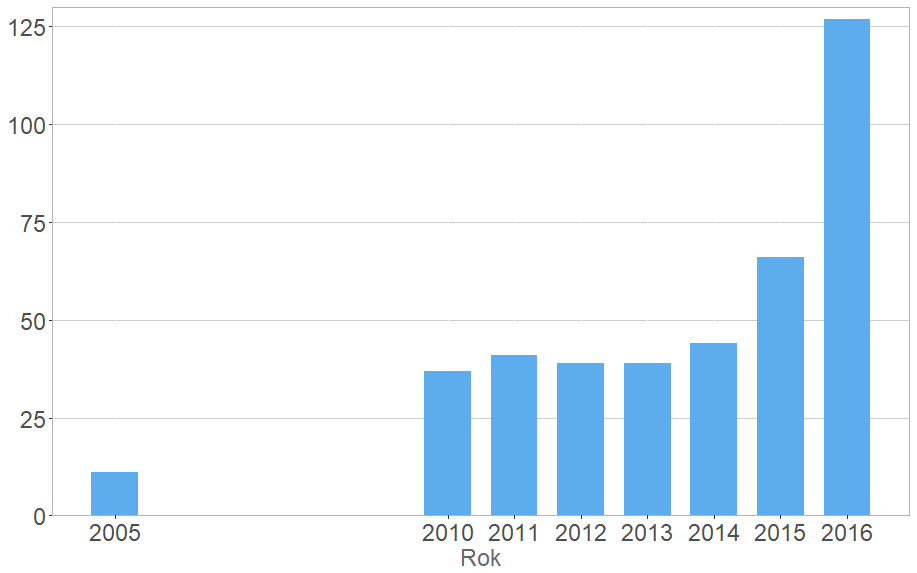
Liczba cudzoziemców (w tys.), którzy otrzymali pozwolenie na pracę w Polsce, dane GUS.
Dla kogo, poza mieszkańcami pogrążonej w kryzysie i wojnie domowej Ukrainy, Polska jest dziś atrakcyjnym kierunkiem emigracji? Kraje, z których napływ ludzi w ostatnich pięciu latach nasilał się i wynosił więcej niż 1500 osób to: Białoruś, Mołdawia oraz Indie. Wyraźnie osłabł natomiast napływ z Chin (prawie sześciokrotnie w ostatnich 6 latach). Wydaje się jasne, że różnica stopnia rozwoju między krajami musi być wystarczająca, by łączny, relatywny koszt emigracji (w tym ten psychologiczny) był mniejszy niż względne korzyści potencjalnego imigranta. Białoruś ma niższe niż Polska PKB per capita (również to liczone w sile nabywczej), ale leży blisko, więc bezpiecznie można założyć, że wszystkie kraje lepiej od niej rozwinięte nie staną się źródłem napływu pracowników do Polski. Na tej zasadzie możemy bezspornie wykluczyć kraje takie jak Gabon, Meksyk czy Iran. Do tej grupy należy też zapewne Botswana, Tajlandia, Chiny, Brazylia czy Algieria. Jednocześnie mieszkańcy krajów bardziej oddalonych od Polski geograficznie i kulturowo niż Ukraina i Białoruś, ponoszą niewątpliwie znacznie większe koszty takiej migracji.
Jeśli w Polsce istnieją silne idiosynkrazje dotyczące kierunków migracji i możliwości integracji cudzoziemców (a debata publiczna jasno wskazuje, że tak jest), warto postawić klarowne pytanie o to, jak owe preferencje przekładają się na konkretne polityki publiczne. A może liczymy jedynie na kryzysy w nieodległym otoczeniu międzynarodowym?
1. Mediana wieku urodzeń stale zmienia się (rośnie), a jej wariancja jest oczywiście spora, więc część dziewczynek z grupy 0-9 jest w istocie córkami kobiet należących do kohorty 10-19, a inna część – kohorty 50-59. Jednak takie “przesunięcia” i nieregularności dotyczą wszystkich kohort, więc ich efekty w większości znoszą się. Zatem choć nie mamy tu substancjalnie trafnego opisu rzeczywistości, to oddaje on faktycznie wpisane w nią trendy.↩
2. Zakładam tu stopniowe, liniowe dochodzenie dzietności do poziomu 2.0.↩
3. Pozwolenia są przedłużane na podstawie oświadczenia pracodawcy, a tych wg UDSC było w 2016 roku 1,26 mln – ta liczba może być z kolei zawyżona w stosunku do realnie pracujących. ZUS podaje liczbę 270 tys. zarejestrowanych Ukraińców. ↩