Poniżej przyglądam się pewnym tendencjom, które pojawiły się w ostatnich latach w sondażach przedwyborczych. Podstawowy wniosek, jaki można wysnuć, mówi, że wzrosła zbieżność predykcji sondażowych, ale spadła ich łączna jakość. Wydaje się, że można to wyjaśnić “efektem peletonu”.
Wyniki badań przedwyborczych przynoszą nam pewną wiedzę zarówno o wynikach nadchodzących wyborów, jak i o przemianach w sektorze badania opinii. Ten wpis jest głównie o tych drugich. Swoje obserwacje oparłem na traktowanych porównawczo sondażach przedwyborczych z lat 2011, 2015, 2019 i 2023 (dane znormalizowane1).
TL;DR: Ludzie nie zmieniają poglądów tak szybko, jak skaczą słupki – waga kampanii jest przeceniana; z wyników sondaży da się wyczytać jak zmienia się sama technologia tego fachu; sondaże “czytają” inne sondaże.
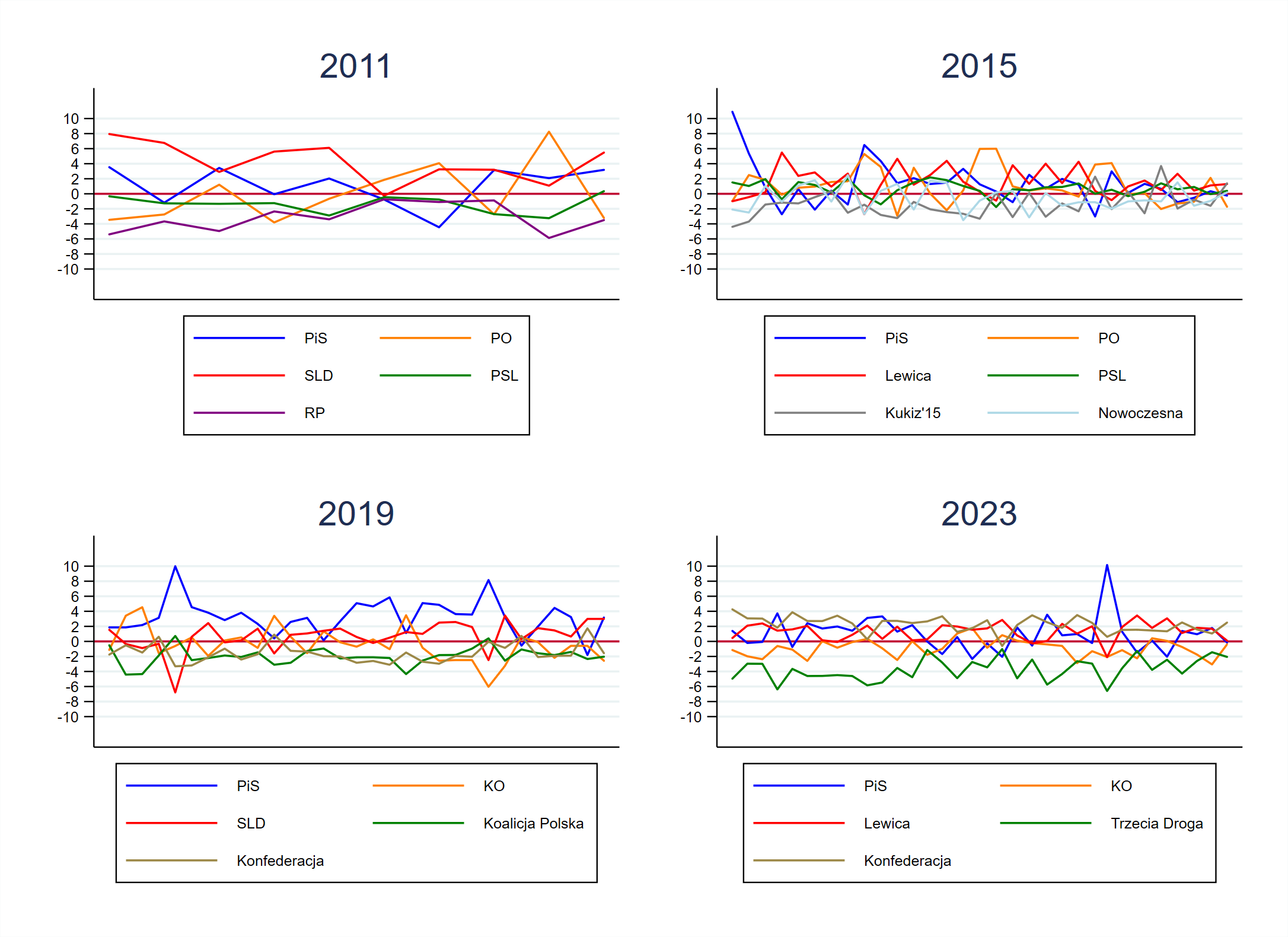
Zacznijmy od tego, że doszukiwanie się trendów w traktowanych łącznie sondażach w czterech ostatnich wyborach było głównie rzeźbieniem w szumie. Jeśli coś było widać, to systematyczne niedoszacowanie jednych komitetów i przeszacowanie innych – właśnie to pokazuje wykres powyżej. Są na nim odchylenia od wyniku wyborów. Tu i dalej konsekwentnie pomijam CBOS z powodów, które streszczam w przypisie2.
Od 2011 roku stabilnie przeszacowane były duże partie i “stare marki” (w 2011 SLD, w 2015 PO, a w 2019 PiS), a niedoszacowane – „nowe marki” o mniejszym poparciu (w 2011 Ruch Palikota, w 2015 Kukiz i .Nowoczesna, w 2019 Koalicja Polska i Konfederacja, a w 2023 Trzecia Droga). Są to względnie regularne prze- i niedoszacowania. Realnie nie było silnego klarownego „trendu” (patrz wykres powyżej).
Szeroko komentowane międzysondażowe „skoki” poparcia (zwykle ze wskazaniem „źródeł wzrostu/spadku” – co jest zawsze tak urocze) były przede wszystkim artefaktami. Owe artefakty miały najprawdopodobniej dwojakie źródło: sam błąd pomiaru, jak i strategię badawczą sondażowni. Pokażę to na liczbach, ale najpierw musicie przecierpieć akademickie przynudzania na temat wyliczania błędów losowych.
Przy wynikach sondaży podawany jest często „maksymalny błąd oszacowania”. Prawie zawsze (zawsze?) jest zwyczajnie niepoprawny, ponieważ ustala się go jedynie na podstawie liczebności próby. Jest on zaniżony, ponieważ nie uwzględnia paru rzeczy. Nie chodzi tu jedynie o błędy systematyczne, które mają wiele źródeł: brzmienie pytań, ich kolejność, korelacje odmów z poglądami itd. (nie będę brnął w ten wątek – te błędy są i tyle, trzeba mieć ich świadomość i starać się je minimalizować). Już sam błąd losowy jest większy niż podawany. Dzieje się tak, ponieważ wszystkie (prove me wrong!) ośrodki badawcze stosują kwotowanie lub wagi analityczne. W przypadku pierwszego w ogóle nie powinno się liczyć błędu jak przy SRS, w przypadku drugiego jest on wyraźnie większy (zmniejsza się effective sample size).

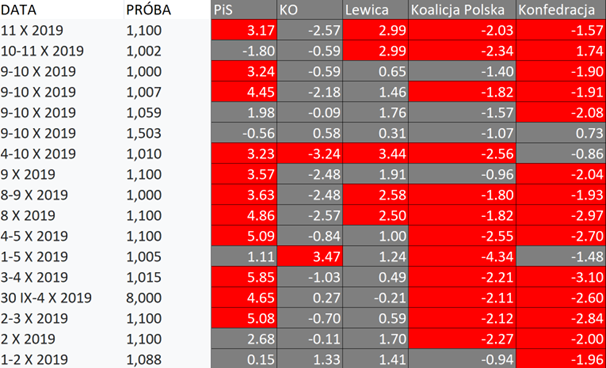
Tzw. „maksymalny błąd oszacowania” łatwo obalić patrząc na jego weryfikację wyborczą. Statystycznie tylko 5 oszacowań punktowych na 100 powinno odchylać się o więcej niż dwa błędy standardowe od wyniku PKW. W ciągu 10 dni przed wyborami w 2019 odchyleń tych było 44 na 85! (zaznaczone na czerwono w tabelce poniżej)
Tylko nie tłumaczcie tego „trendem”, proszę…
Oczywiście niektórzy pomylili się bardziej niż inni. Jednak żadna pracownia nie była stabilnym liderem predykcji na przestrzeni wielu lat – sukces nie jest więc replikowalny. Nie da się jednoznacznie wskazać “najlepszej kuchni”. Tej “kuchni” przede wszystkim praktycznie nie znamy. Publikowane notki zawierają jedynie informacje szczątkowe – nic tam nie ma o doborze respondentów, response rate, ważeniu, za mało jest o filtrowaniu. Trudno więc ocenić realne obciążenie poszczególnych wyników. Informacje metodologiczne traktowane są w znacznej mierze jak sekret korporacyjny, a nie sposób na budowanie społecznej wiarygodności. (Tym elementem powinny próbować się wyróżnić większe pracownie – zwłaszcza w kontekście tendencji o których napiszę dalej.)
Czy bez wiedzy insiderskiej da się coś powiedzieć o współczesnej “kuchni”? Wydaje mi się, że tak.
Tu wróćmy do ważenia. Można je przeprowadzić wg szeregu różnych kryteriów, np. cech społeczno-demograficznych, retrospektywnych deklaracji ws. wcześniejszych głosowań itp., a dokładny wybór sposobu ważenia i filtrowania jest zawsze w pewnym stopniu arbitralny. To powoduje, że nie mamy przeważnie do czynienia z “czystymi” sondażami (w sensie surowego rozkładu odpowiedzi), a z sondażowymi prognozami (dane przetworzone ekspercko). Co ważne – komponent arbitralny pozwala uwzględnić w nich dodatkowe informacje kontekstowe… w tym średnią wyników innych pracowni.
Update: Poniżej przedstawiam przeciętne odchylenie pojedynczego wyniku sondażu od ich łącznej średniej w miesiącu poprzedzającym wybory parlamentarne (tylko komitety “ponadprogowe”). Jak widać, od 12 lat rozrzut wyników systematycznie zmniejsza się.

Rosnąca zbieżność wyników sugeruje, że pracownie starają się lekko nawigować względem siebie, co jest decyzją względnie racjonalną biznesowo, zwłaszcza w przypadku ośrodków robiących tanie badania, świadomych słabości własnych danych. jest to po prostu optymalizacja jakości do kosztu z wykorzystaniem darmowego “surowca”. Większość sondaży zamawiają media, im zależy na klikalności/oglądalności, ale nie są w stanie zapłacić kilkuset tysięcy złotych w każdy weekend. Powstaje więc wiele sondaży względnie tanich, o niższych standardach, niż akademickie. Reprezentatywność tych sondaży jest względnie niska. Dostępne są jednak średnie z wielu sondaży, czyli ekwiwalent “powiększenia próbki”. Dlaczego nie skorzystać?
Jak wie każdy zawodowy kolarz, nie oglądanie się na resztę peletonu jest ryzykowne. Jazda z „peletonem” stanowi rodzaj ubezpieczenia. Większa zbieżność powoduje, że cały sektor sondażowy pospołu wygra lub przegra. Kto jest w stawce, ten może przynajmniej nie wypadnie z rynku. Co więcej, uwzględnianie wyników innych sondaży jest jak jechanie za plecami konkurenta – trochę lżej się pedałuje.
O ile “efekt peletonu” (tzw. herding) jest racjonalny z punktu widzenia przynajmniej części pracowni badawczych, to niekoniecznie jest on korzystny dla konsumentów sondaży. Większa spójność wyników tworzy pozór pewności prognozy. Gdyby nie wspomaganie zbieżności wyników (zwłaszcza większych partii), bardziej wiarygodna byłaby też średnia z wielu sondaży. Wykorzystywanie informacji kontekstowej dokłada bowiem nowe źródło błędu systematycznego. Wracając do metafory kolarskiej – często peleton wjeżdża na metę jako pierwszy, ale nie raz zdarza się, że oglądanie się na siebie nawzajem prowadzi do przesadnego obniżenia wspólnego tempa. Wówczas peleton przegrywa.

Jakościowej korekty prognoz – jeśli nastąpi – można oczekiwać dopiero w ostatnim tygodniu przed wyborami, tuż przed klarowną weryfikacją jakości oszacowań. Wszelkie wcześniejsze odchylenia można tłumaczyć “trendami poparcia”, które są w zasadzie nieweryfikowalne.
„Korekta” na ostatniej prostej nie zawsze jest skuteczna (choć zakładam, że wszyscy dokładają wówczas większych starań), ale okazała się taka w 2015 roku. Tu jednak znajdujemy dodatkową przesłankę, aby sądzić, że trafne ważenie odgrywa bardzo dużą rolę w poprawnym szacowaniu wyników. W maju 2015 odbyły się wybory prezydenckie. Retrospektywne pytanie o sposób głosowania w maju były jesienią znacznie lepszą „kotwicą” kalibracji wag, niż gdy czyni się to w oparciu o deklarację głosowania cztery lata wcześniej. Po prostu fakt, że ktoś zadeklarował głosowanie na Dudę/Komorowskiego był znakomitym predyktorem głosowania w październiku. To dlatego udało się wówczas stworzyć lepsze oszacowania. W tygodniu przed tymi wyborami na 66 oszacowań punktowych (11 sondaży * 6 komitetów z > 5pp) powyżej błędu losowego znalazło się jedynie 15 (wciąż więcej niż oczekuje statystyka indukcyjna, ale porównajcie to z ponad połową przekroczeń w 2019!)
15 X poznamy nie tylko zwycięzcę wyborów, ale również zwycięzcę prognoz. Czy będzie to zwycięstwo wypracowane na podstawie finezyjnej metodologii, żelaznej dyscypliny i pełnej poświęceń pracy ankieterów? Mam nadzieję. Ale trudno będzie wykluczyć zwykły fart. Socjologia w zakresie prognoz rywalizuje raczej z meteorologią czy sejsmologią, a niż z astronomią. Z dwutygodniowym wyprzedzeniem bardzo trudno przewidzieć czy potrzebny będzie parasol.
Na koniec niezbędny jest DISCLAIMER: Nie oznacza to wcale, że sondaże i prognozy są bezwartościowe i że nic nie wiadomo. Przeciwnie, dzięki sondażom wiemy całkiem sporo i możemy być świadomymi wyborcami. Ale warto znać specyfikę tego “barometru” i brać na nią poprawkę.
PS. Wiadomo już, które sondaże okazały się najbliższe wynikom wyborów (przy czym można to mierzyć na kilka różnych sposobów):
https://x.com/spoleczenstwopl/status/1732776755264405598?s=20
Przypisy:
- Wyniki podawane przez poszczególne pracownie nie są bezpośrednio porównywalne, choćby ze względu na rozbieżne odsetki odpowiedzi “nie wiem”. Żeby zestawiać je między sobą i z PKW, powinny sumować się do 100. Właśnie temu służy normalizacja. Warto zauważyć, że czym wyższy odsetek odpowiedzi “nie wiem”, tym łatwiej jest później pracowni bronić się, że to właśnie w niej zaszyte były brakujące punkty procentowe. Skoro i tak stosowane są wagi, a niezdecydowani są dopytywani o poglądy, prognozy powinny to uwzględniać. ↩︎
- CBOS od dawna mierzy się z silnym house effect, którego jest świadom i którego mimo wszystko nie koryguje. Zachowuje natomiast względnie spójną metodologię, dość istotną z punktu widzenia śledzenia trendów – co jest pewną wartością tych badań (#reliablebiaspride). Powoduje to, że CBOSu nie należy traktować jak podmiotu z rynku sondaży przedwyborczych. Jego nadrzędnym celem nie jest prognoza wyniku PKW. Waży tylko na demografikach. Nie ma medialnych zleceniodawców, ale mecenasa, który (jak sądzę) za bardzo nie życzy sobie jakichkolwiek nowinek. ↩︎